MMM with time-varying parameters (TVP)#
In classical marketing mix models, the effect of advertising (or other factors) on sales is assumed to be constant over time. Similarly, the baseline sales—what you would have sold without marketing—is also assumed to be constant. This is a simplification that typically doesn’t match reality. There will be times when, for various reasons, your ads are more effective, or when your product just sells better.
This time-varying effect is something we can capture with a time-varying parameter. In the context of a marketing mix model, this could be changing trends, unexpected events, and other external factors that are not controlled for. For example, if you sell sunglasses or ice cream, an unusually sunny spring will impact both your baseline sales and likely also the effect of your ads on short-term sales.
👉 In this notebook, we demonstrate how—and when—to use a time-varying parameter for intercept in an MMM, using pymc-marketing’s MMM model.
The API is straightforward:
mmm = MMM(
date_column="date",
target_column="y",
channel_columns="channels",
control_columns="control",
dims=("geo",),
adstock=adstock,
saturation=saturation,
yearly_seasonality=2,
model_config=model_config,
time_varying_intercept=True, # 👈 This is it!
)
🤓 Under the hood, the time-varying intercept is modeled as a Gaussian Process (specifically a Hilbert Space GP to speed things up), constrained to \(\mu=1\) and then multiplied by a baseline intercept. So if the sampler infers that the baseline intercept is 1000 sunglasses sold per week, then the GP models the percentage deviation from that, over time. Have a look at the implementation of MMM for concrete structural details.
Below, we give three simple usage examples:
Yearly seasonality: The intercept is a cosine function with a period of one year. Normally, one would use a Fourier basis to model seasonality, but let’s see what happens when we use a time-varying intercept 🤷♂️.
Upward trending sales: The intercept is a linearly increasing function, mimicking overall sales growth not explained by marketing or controls. Again, you would normally use a linear increasing control variable for this, but let’s see what happens when we use a time-varying parameter.
Unexpected events: The intercept is a flat line, except for intermittent, randomly placed spikes/dips. This is a more realistic scenario, where the effect of marketing is not constant, but rather varies due to various unexpected factors.
We conclude that while the GP-based time-varying intercept can technically do the job for seasonality and trends, it’s not the most efficient way to do so (choose a Fourier basis or linear trend instead). However, to capture unexpected events that no other variable can explain, it’s very powerful 💪.
import warnings
from datetime import date
import arviz as az
import matplotlib.pylab as plt
import numpy as np
import numpy.typing as npt
import pandas as pd
from pymc_extras.prior import Prior
from pymc_marketing.hsgp_kwargs import HSGPKwargs
from pymc_marketing.mmm import GeometricAdstock, LogisticSaturation
from pymc_marketing.mmm.multidimensional import MMM
from pymc_marketing.paths import data_dir
SEED = sum(map(ord, "Time varying parameters are awesome!"))
rng = np.random.default_rng(SEED)
warnings.filterwarnings("ignore")
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina";
Load synthetic data#
For this example, we load some simulated consumer goods marketing spend/control data.
→ Load input data#
data_path = data_dir / "mock_cgp_data.csv"
DATA = pd.read_csv(data_path, parse_dates=["Weeks"])
# Define which columns are media and control
COORDS = {
"media": ["Google Search", "DV360", "Facebook", "AMS", "TV", "VOD", "OOH", "Radio"],
"control": ["Numeric Distribution", "RSP", "Promotion"],
"week": DATA["Weeks"],
}
DATA.describe()
| Weeks | Google Search | DV360 | AMS | TV | VOD | OOH | Radio | Numeric Distribution | RSP | Promotion | target1 | target2 | target_seasonal | target_upwards | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 365 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 | 365.000000 |
| mean | 2023-07-03 00:00:00.000000256 | 2.217827 | 3.445572 | 2.098098 | 1.706826 | 14.033553 | 2.970981 | 7.118491 | 1.543534 | 0.796888 | 3.854293 | 0.911618 | 6.812159 | 10.794462 | 12.272323 | 9.767250 |
| min | 2020-01-06 00:00:00 | 1.047788 | 1.601873 | 0.774239 | 0.619639 | 0.000000 | 0.420461 | 0.000000 | 0.000000 | 0.537044 | 3.456516 | 0.708443 | 2.279161 | 5.944537 | 7.911417 | 4.948952 |
| 25% | 2021-10-04 00:00:00 | 1.619056 | 2.547655 | 1.458022 | 1.151885 | 9.271226 | 1.802338 | 4.367724 | 0.709456 | 0.744768 | 3.772808 | 0.866010 | 5.130973 | 9.668964 | 10.623038 | 8.540390 |
| 50% | 2023-07-03 00:00:00 | 1.925589 | 3.039579 | 1.764620 | 1.442006 | 12.703907 | 2.629420 | 6.313286 | 1.139943 | 0.810860 | 3.871714 | 0.916832 | 6.799721 | 10.923904 | 12.408570 | 9.977761 |
| 75% | 2025-03-31 00:00:00 | 2.386296 | 3.747809 | 2.233468 | 1.796656 | 16.428118 | 3.455183 | 8.813714 | 2.312537 | 0.855192 | 3.934013 | 0.963584 | 8.428587 | 11.978078 | 13.838269 | 11.090633 |
| max | 2026-12-28 00:00:00 | 5.924566 | 8.522803 | 8.867833 | 6.394341 | 42.777737 | 9.464257 | 34.234847 | 5.036427 | 0.940265 | 4.168038 | 1.000000 | 12.859009 | 15.430793 | 18.007455 | 14.319832 |
| std | NaN | 0.923242 | 1.357814 | 1.089417 | 0.935993 | 7.359857 | 1.694734 | 4.708247 | 1.156565 | 0.082797 | 0.142821 | 0.066310 | 2.110028 | 1.812301 | 2.019333 | 1.874080 |
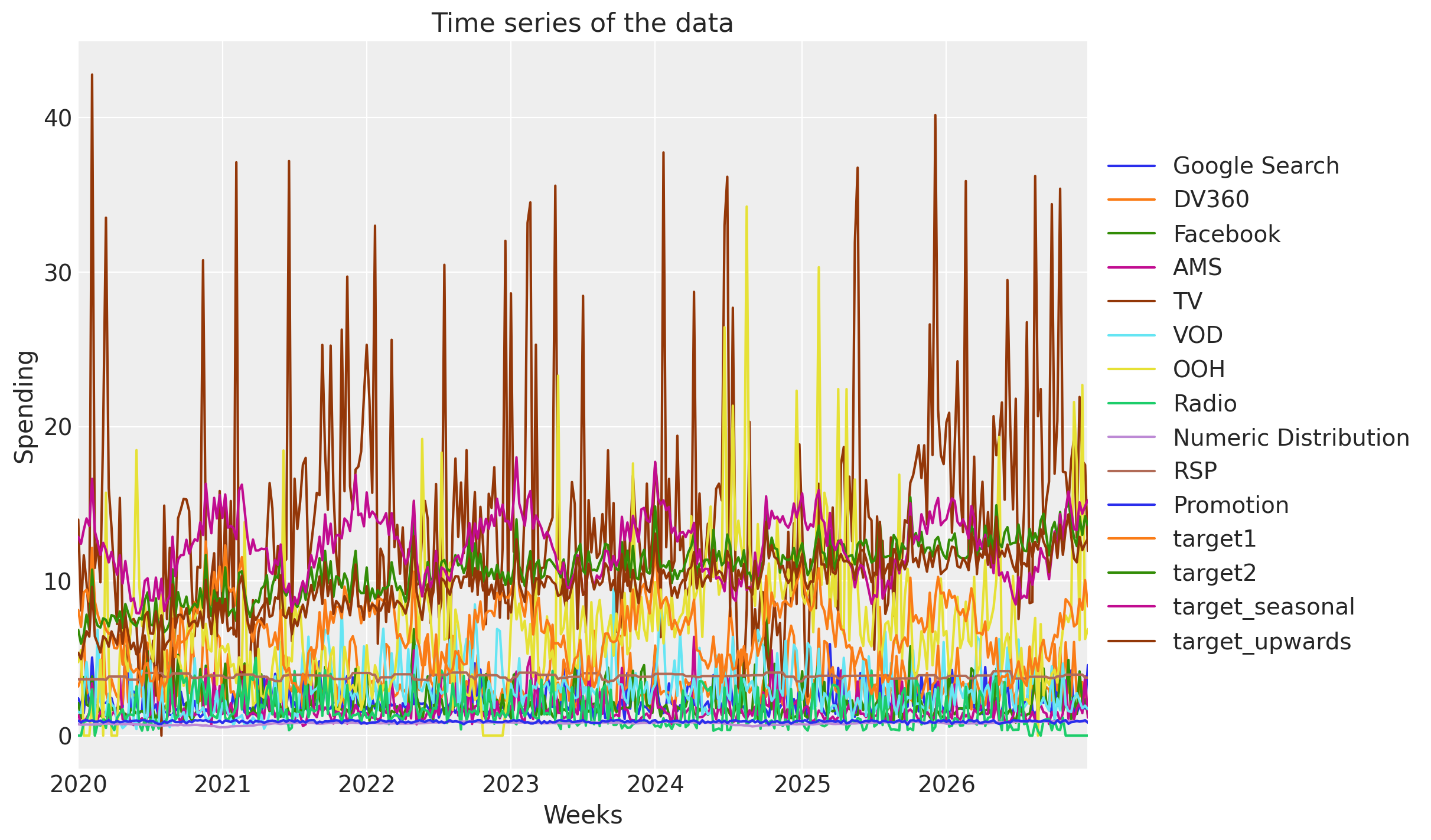
_, ax = plt.subplots()
DATA.set_index("Weeks").plot(ax=ax)
ax.set_title("Time series of the data")
ax.set_ylabel("Spending")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5));
Helper functions for synthetic data generation#
We define a helper function synthesize_and_plot_target to generate synthetic target variables based on a supplied synthetic_intercept. The function adds:
Channel contributions: Small linear effects from
Google Search,TV, andFacebook.Control contributions: Larger linear effects from
Numeric DistributionandPromotion.Noise: Random Gaussian noise.
This allows us to create different scenarios (seasonality, trends, events) by just varying the intercept component while keeping the media/control effects consistent.
We will use this as a comparison point for the models we will be building!
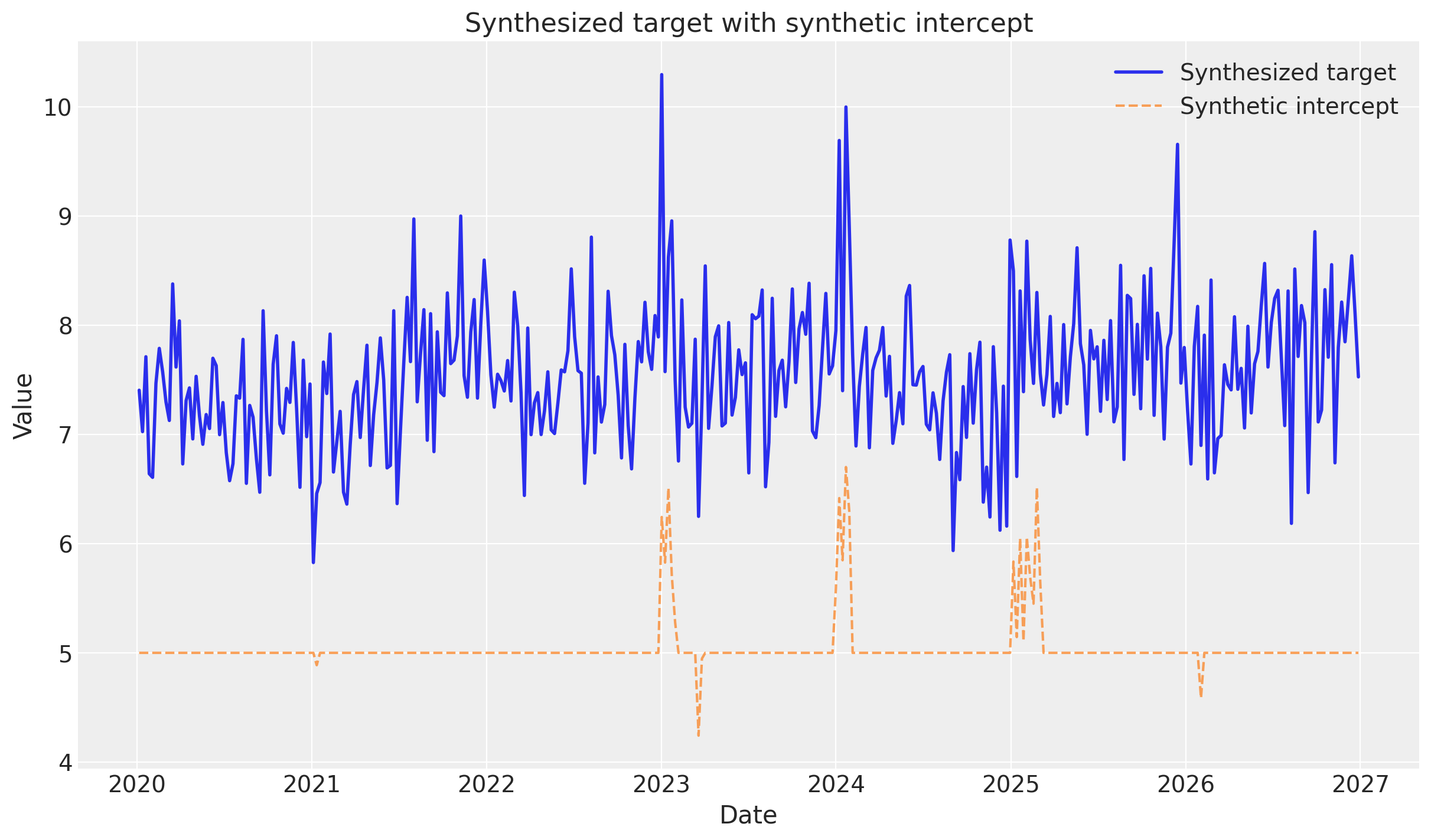
def synthesize_and_plot_target(synthetic_intercept: npt.NDArray) -> npt.NDArray:
"""Synthesize target values from synthetic intercept plus simplified channel/control effects.
This is a simplified data generation process for demonstration purposes.
"""
# Simple contribution from channels (sum of a few channels with small coefficients)
channel_contribution = (
0.05 * DATA["Google Search"].values
+ 0.03 * DATA["TV"].values
+ 0.02 * DATA["Facebook"].values
)
# Simple contribution from controls
control_contribution = (
1.5 * DATA["Numeric Distribution"].values + 0.8 * DATA["Promotion"].values
)
# Add some noise
noise = rng.normal(0, 0.5, size=len(synthetic_intercept))
# Combine all contributions
target = synthetic_intercept + channel_contribution + control_contribution + noise
# Visualize
_, ax = plt.subplots()
ax.plot(DATA["Weeks"], target, label="Synthesized target", linewidth=2)
ax.plot(
DATA["Weeks"],
synthetic_intercept,
label="Synthetic intercept",
linestyle="--",
alpha=0.7,
)
ax.set_title("Synthesized target with synthetic intercept")
ax.set_xlabel("Date")
ax.set_ylabel("Value")
ax.legend()
return target
Example 1: Yearly seasonality#
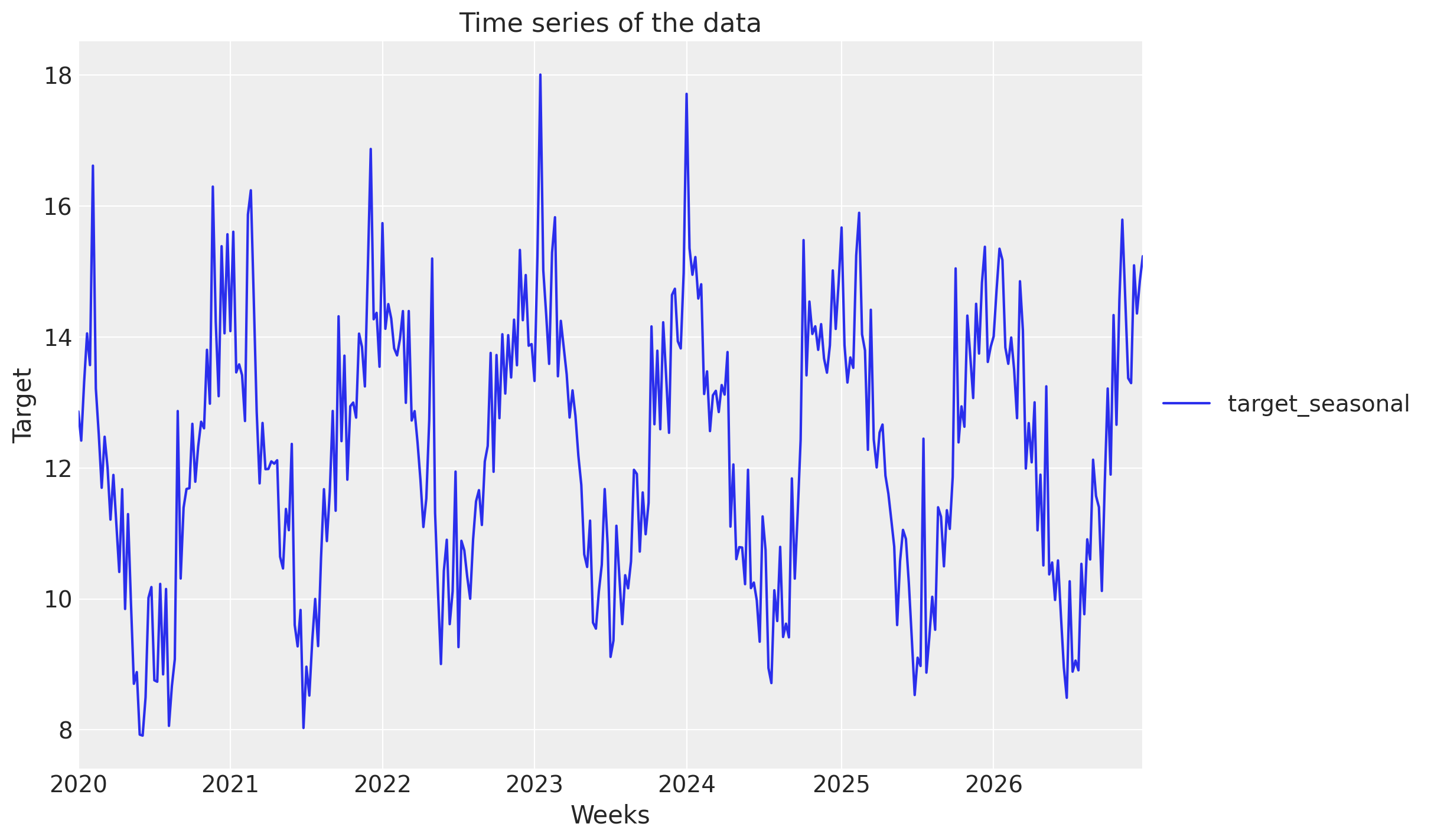
A common pattern in consumer goods sales is that sales are higher in the summer and lower in the winter, or reverse. In this example, we will work with sales that follow this pattern—by letting the synthetic intercept be a cosine wave—and then see if the model can recover this using a time-varying intercept.
_, ax = plt.subplots()
DATA[["Weeks", "target_seasonal"]].set_index("Weeks").plot(ax=ax)
ax.set_title("Time series of the data")
ax.set_ylabel("Target")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5));
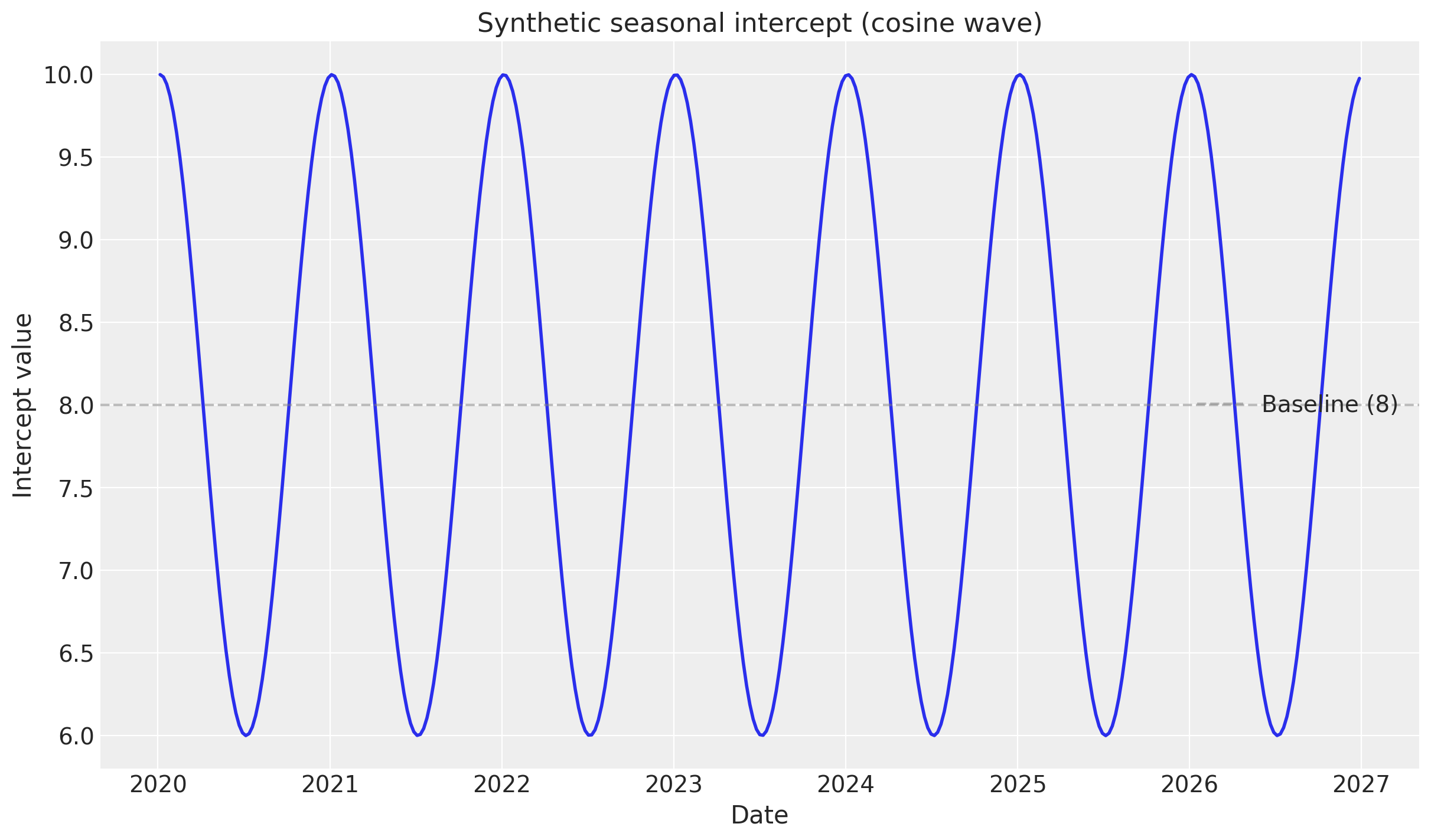
# Create synthetic seasonal intercept: cosine wave with yearly period
# Week number in the series
week_numbers = np.arange(len(DATA))
# Cosine with period of 52.18 weeks (one year), amplitude of 2, baseline of 8
synthetic_intercept_seasonal = 8 + 2 * np.cos(2 * np.pi * week_numbers / 52.18)
# Visualize the synthetic intercept
_, ax = plt.subplots()
ax.plot(DATA["Weeks"], synthetic_intercept_seasonal, linewidth=2)
ax.set_title("Synthetic seasonal intercept (cosine wave)")
ax.set_xlabel("Date")
ax.set_ylabel("Intercept value")
ax.axhline(y=8, color="gray", linestyle="--", alpha=0.5, label="Baseline (8)")
ax.legend();
→ Split into train and test#
We split the data into train and test sets, so we may later display out-of-sample predictive performance.
SPLIT_N = 52
data_train = DATA.iloc[:-SPLIT_N]
data_test = DATA.iloc[-SPLIT_N:]
→ Fit model#
We fit the model with default settings, except specifying a HalfNormal prior on the baseline intercept. This is because we know that the baseline sales are positive, for a model like this.
# L= (1 + 0.3) * ((data_train.shape[0]) / 2 ) (i.e., scaler number of dates, i.e.). the domain of the GP)
# We divide by 2 because we are centering the GP on the mean of the data. So the "box" [-L/2, L/2]
# is the domain of the GP.
(1 + 0.2) * ((data_train.shape[0]) / 2)
sampler_config = {
"chains": 4,
"draws": 1_000,
"tune": 1_200,
"nuts_sampler": "nutpie",
"nuts_sampler_kwargs": {"backend": "jax", "gradient_backend": "jax"},
"target_accept": 0.85,
}
model_config = {
"intercept": Prior(
"LogitNormal", mu=0, sigma=0.1
), # 👈 Positive baseline intercept
"gamma_control": Prior("Normal", mu=0, sigma=2, dims="control"),
"intercept_tvp_config": HSGPKwargs(
m=500,
L=188,
eta_lam=5.0,
ls_mu=5.0,
ls_sigma=10.0,
),
"adstock_alpha": Prior("Beta", alpha=1, beta=3, dims="channel"),
"saturation_lam": Prior("Gamma", alpha=3, beta=1, dims="channel"),
"saturation_beta": Prior("HalfNormal", sigma=2, dims="channel"),
}
def create_and_fit_mmm(
data: pd.DataFrame,
target: pd.Series,
target_column: str,
) -> MMM:
mmm = MMM(
date_column="Weeks",
target_column=target_column,
channel_columns=COORDS["media"],
control_columns=COORDS["control"],
adstock=GeometricAdstock(l_max=10),
saturation=LogisticSaturation(),
time_varying_intercept=True, # 👈 Keep this as True
sampler_config=sampler_config,
model_config=model_config,
)
# Build the model
mmm.build_model(X=data_train, y=data_train[target_column])
# Add original scale contribution variables for later analysis
mmm.add_original_scale_contribution_variable(
var=[
"channel_contribution",
"control_contribution",
"intercept_contribution",
"y",
]
)
# Fit the model
mmm.fit(data, target, random_seed=rng)
return mmm
mmm_seasonal = create_and_fit_mmm(
data_train, data_train["target_seasonal"], "target_seasonal"
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 41 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2200 | 0 | 0.07 | 63 | |
| 2200 | 0 | 0.06 | 63 | |
| 2200 | 0 | 0.07 | 63 | |
| 2200 | 0 | 0.06 | 63 |
→ Posterior predictive checks#
We visualize the posterior predictive distribution, to understand how well the model fits the data.
Sales
First, we consider predicted versus actual sales both within- and out-of-sample.
def plot_posterior_predictive(
mmm: MMM,
target_series: pd.Series,
label_y: float,
) -> plt.Axes:
# Sample posterior predictive in whole data range (train and test)
if "posterior_predictive" not in mmm.idata:
mmm.sample_posterior_predictive(
DATA,
extend_idata=True,
var_names=[
"channel_contribution",
"control_contribution",
"intercept_contribution",
"y_original_scale",
"intercept_baseline",
"intercept_contribution",
],
)
# Plot the posterior predictive using the new API
_fig, axes = mmm.plot.posterior_predictive(var=["y_original_scale"])
ax = axes[0][0]
# Plot actual observed values
ax.plot(
mmm.idata.posterior_predictive.date,
target_series,
color="black",
label="Actual",
linewidth=2,
zorder=10, # Ensure actuals are plotted on top
)
# Add train/test split line
split_index = DATA.shape[0] - SPLIT_N
ax.axvline(
mmm.idata.posterior_predictive.date[split_index].values,
color="black",
linestyle="--",
)
ax.text(
mmm.idata.posterior_predictive.date[split_index].values,
label_y,
"Train/test split\n",
verticalalignment="center",
horizontalalignment="center",
fontsize=16,
rotation=90,
)
# Update legend to ensure "Actual" is included
ax.legend(loc="best")
return ax
def plot_posterior_predictive_zoomed(
mmm: MMM,
target_series: pd.Series,
xlim: tuple[date, date],
arrow_xy: tuple[date, float],
arrowtext_xy: tuple[date, float],
label_y: float,
annotation_text="Predictions start\ndiverging around here",
) -> plt.Axes:
ax = plot_posterior_predictive(mmm, target_series, label_y)
ax.set_title("Posterior Predictive Check (zoomed in)", y=1.2)
ax.set_xlim(xlim)
ax.annotate(
annotation_text,
xy=arrow_xy,
xytext=arrowtext_xy,
arrowprops=dict(facecolor="black", shrink=1, width=0.2, headwidth=6),
fontsize=12,
)
return ax
# Plot the whole period
ax = plot_posterior_predictive(mmm_seasonal, DATA["target_seasonal"], label_y=-2)
# Zoom in on the years around the train/test split
ax = plot_posterior_predictive_zoomed(
mmm_seasonal,
DATA["target_seasonal"],
xlim=(date(2025, 1, 1), date(2026, 12, 1)),
arrow_xy=(date(2026, 3, 20), 14),
arrowtext_xy=(date(2026, 4, 20), 21),
label_y=-2,
)
Sampling: [intercept_baseline, y]
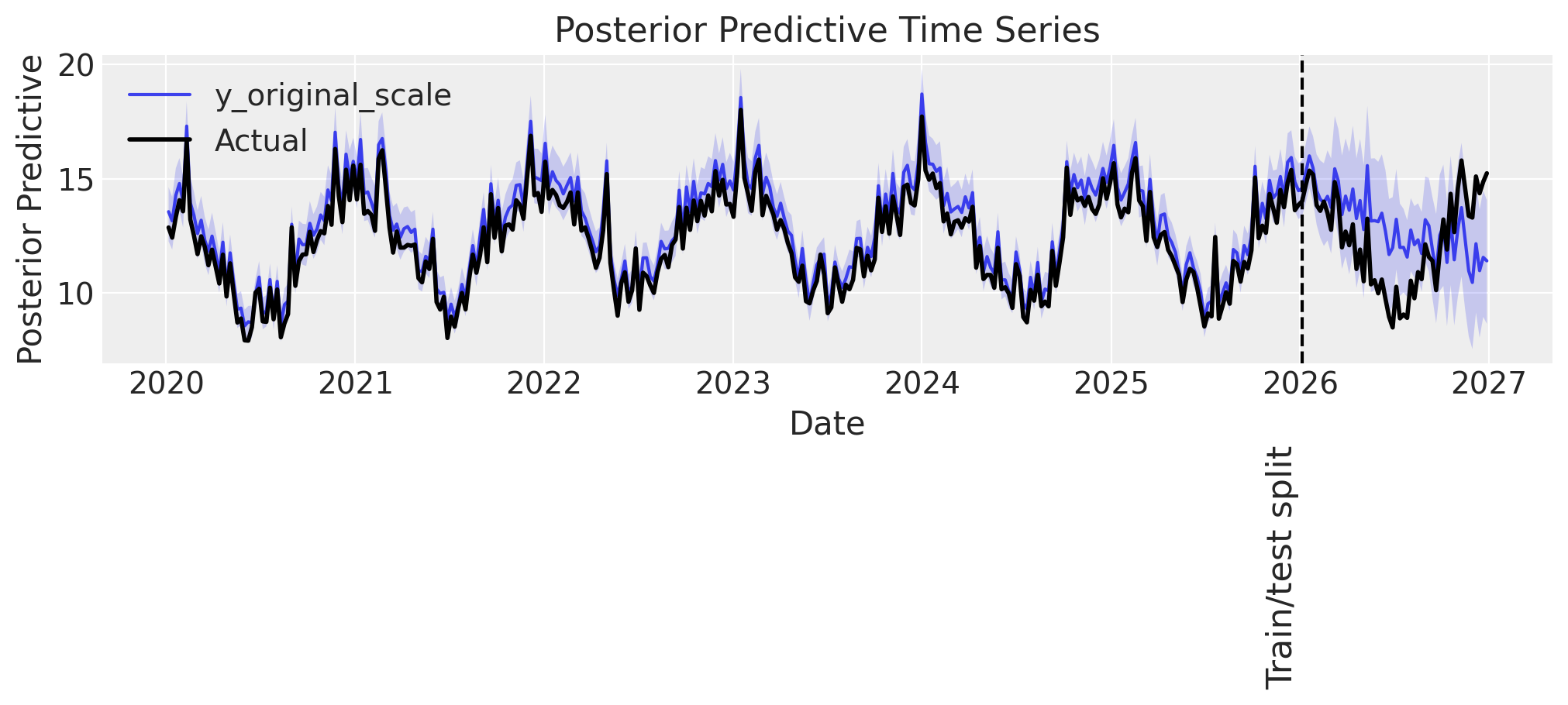
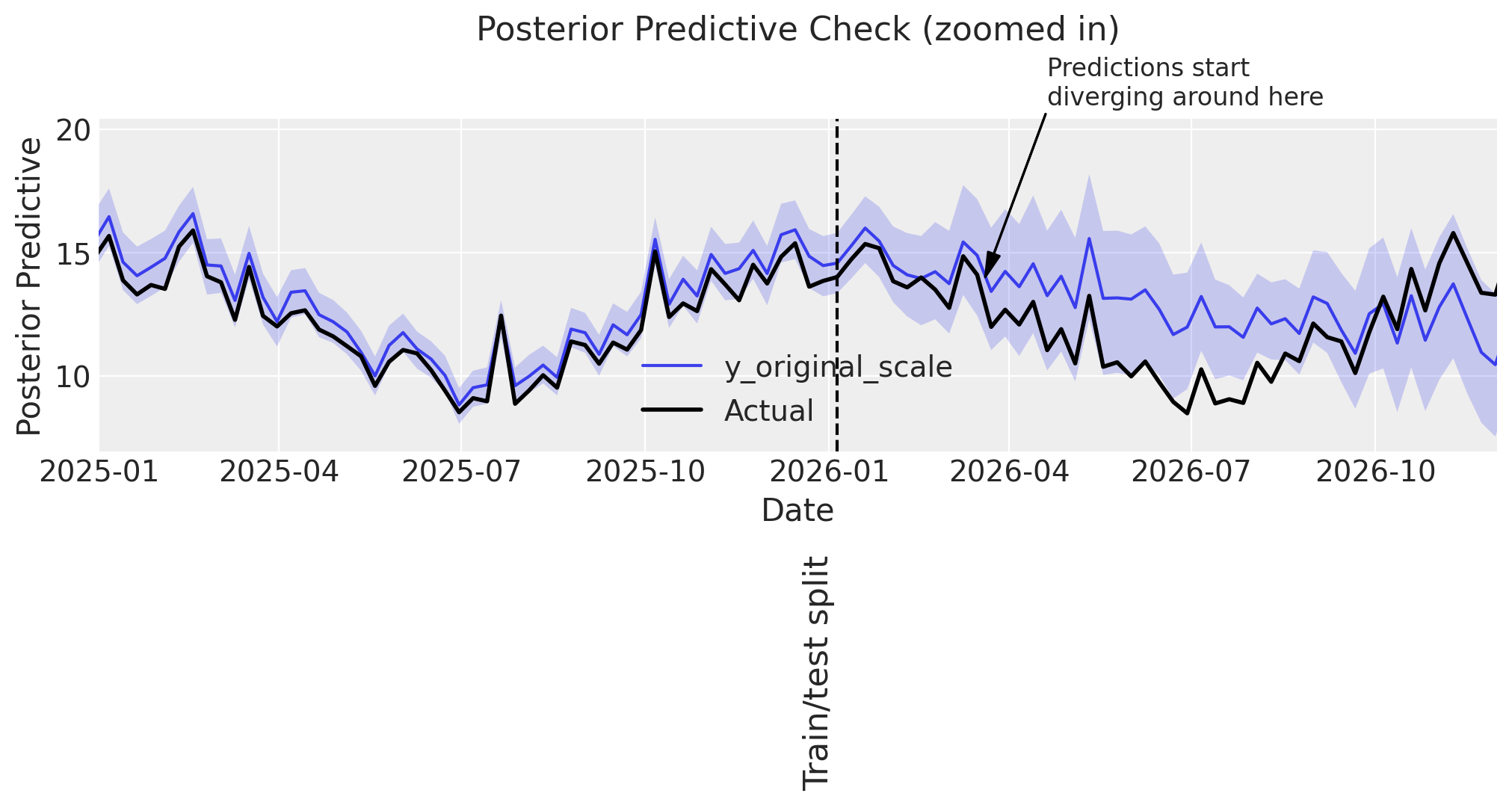
Some observations:
👍 The model performs well in-sample.
🤷♂️ The model predicts accurately up to ~3 months into the test set, then starts to deviate.
Since the most important utility of an MMM is to model the individual channel, control, and intercept contributions in sample, this out-of-sample error is not a particular worry. For scenario planning or backtesting, the decent performance in the 3 months after the training period ends, is likely sufficient, and in case a longer prediction window were desired, one would not want to use a GP to model seasonality, but rather a Fourier basis.
Predicting intercept
We can dig one step deeper, and display the posterior predictive distribution of the time-varying intercept. Let’s first display the fitted baseline intercept (it should be close to 8).
def print_base_intercept(mmm):
print(
f"intercept_contribution: {mmm.idata['posterior']['intercept_contribution_original_scale'].mean().item(): 0.3f}", # noqa: E501
)
print_base_intercept(mmm_seasonal)
intercept_contribution: 8.404
🎉 That indeed is close to the true value of 8.
Now, let’s visualize the posterior predictive distribution of the time-varying intercept, against the actual time-varying intercept.
def plot_intercept_posterior_predictive(
mmm: MMM,
synthetic_intercept: npt.NDArray,
label_y: float,
) -> plt.Axes:
# Get the posterior predictive of the intercept_contribution (which includes time-varying component)
# For multidimensional MMM, we need to handle the proper dimensions
# intercept_contribution has dims: (date, chain, draw) or (date, chain, draw, *dims)
# Sample posterior predictive if not already done
if "intercept_contribution" not in mmm.idata.posterior_predictive:
raise ValueError(
"intercept_contribution not found in posterior_predictive. \
Make sure the model was fit with time_varying_intercept=True"
)
intercept_posterior = mmm.idata.posterior_predictive.intercept_contribution
# Get mean across chain and draw dimensions
intercept_posterior_mean = (
intercept_posterior.mean(dim=["chain", "draw"]).values
* mmm.scalers._target.values.item()
)
# Get HDI
intercept_posterior = (
intercept_posterior.to_numpy() * mmm.scalers._target.values.item()
)
# Plot posterior intercept versus actual
_, ax = plt.subplots()
ax.set_title("Posterior intercept vs actual")
# Get dates from the posterior_predictive coords (not model.coords)
# This includes both train and test periods
dates = mmm.idata.posterior_predictive.date
n_dates = len(dates)
# Slice the synthetic intercept to match the posterior_predictive length
synthetic_intercept_slice = synthetic_intercept[:n_dates]
ax.plot(dates, intercept_posterior_mean, label="Posterior mean")
az.plot_hdi(
dates,
intercept_posterior,
hdi_prob=0.94,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": f"{0.94:.0%} HDI"},
ax=ax,
)
ax.plot(
dates, synthetic_intercept_slice, label="Actual", color="black", linewidth=2
)
# Add train/test split line
split_index = DATA.shape[0] - SPLIT_N
ax.axvline(
dates[split_index].values,
color="black",
linestyle="--",
alpha=0.5,
)
ax.text(
dates[split_index].values,
label_y,
"Train/test split\n",
verticalalignment="center",
horizontalalignment="center",
fontsize=16,
rotation=90,
)
ax.legend()
return ax
plot_intercept_posterior_predictive(
mmm_seasonal, synthetic_intercept_seasonal, label_y=-1
);
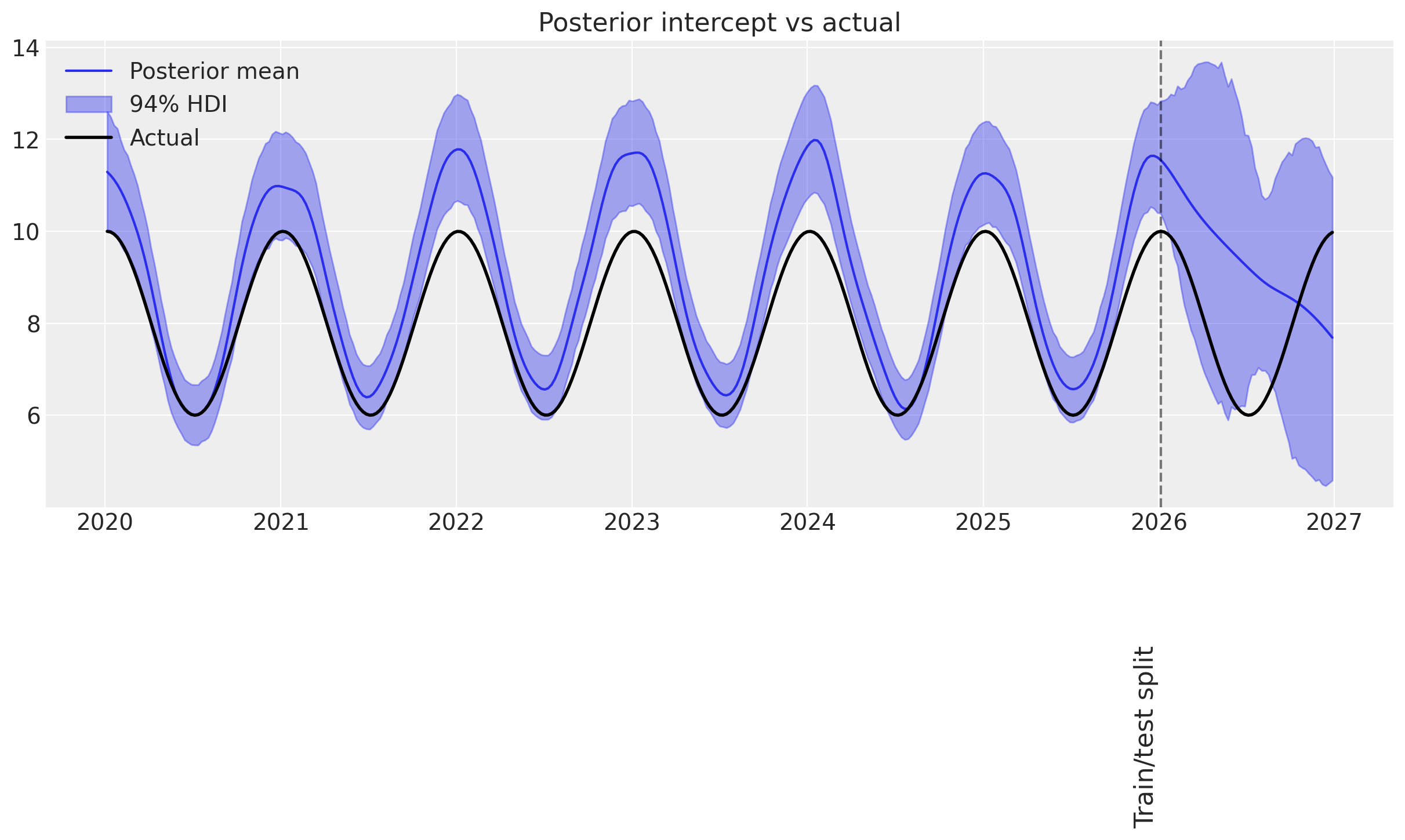
Visualizing this, it’s clear that:
👌 In-sample it gets the synthetic trend almost exactly right!
👎 Out-of-sample, the uncertainty blows up. This is expected, as GPs are typically not great at extrapolating far from the training data.
Example 2: Upward trending sales#
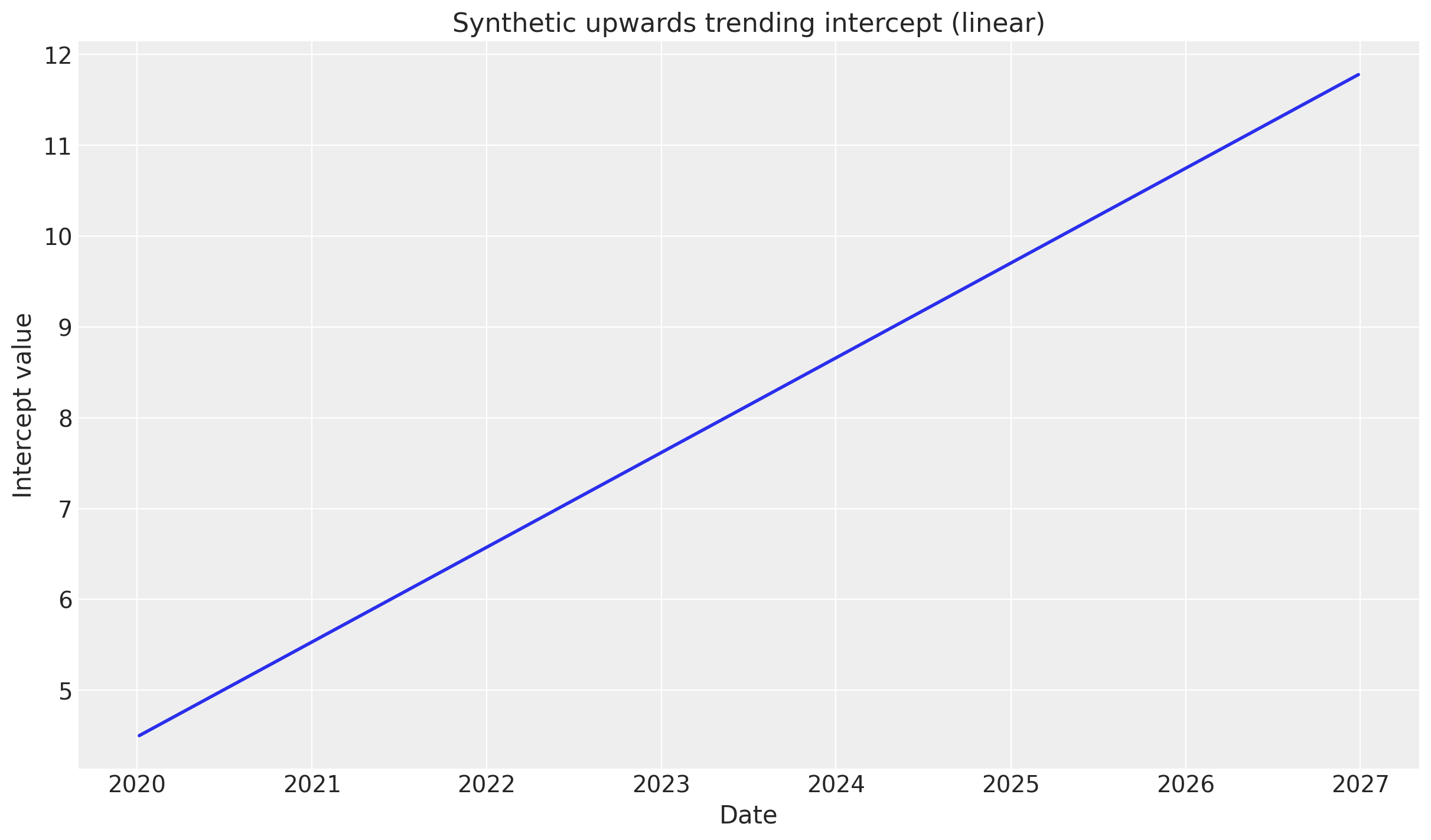
This section repeats the steps above, except with a linearly increasing intercept with mean 4.5, to mimic upward trending sales.
→ Simulate sales#
# Create synthetic upwards trending intercept: linear increase
week_numbers = np.arange(len(DATA))
# Linear trend starting at 4.5, increasing by ~0.02 per week
synthetic_intercept_upwards = 4.5 + 0.02 * week_numbers
# Visualize the synthetic intercept
_, ax = plt.subplots()
ax.plot(DATA["Weeks"], synthetic_intercept_upwards, linewidth=2)
ax.set_title("Synthetic upwards trending intercept (linear)")
ax.set_xlabel("Date")
ax.set_ylabel("Intercept value");
_, ax = plt.subplots()
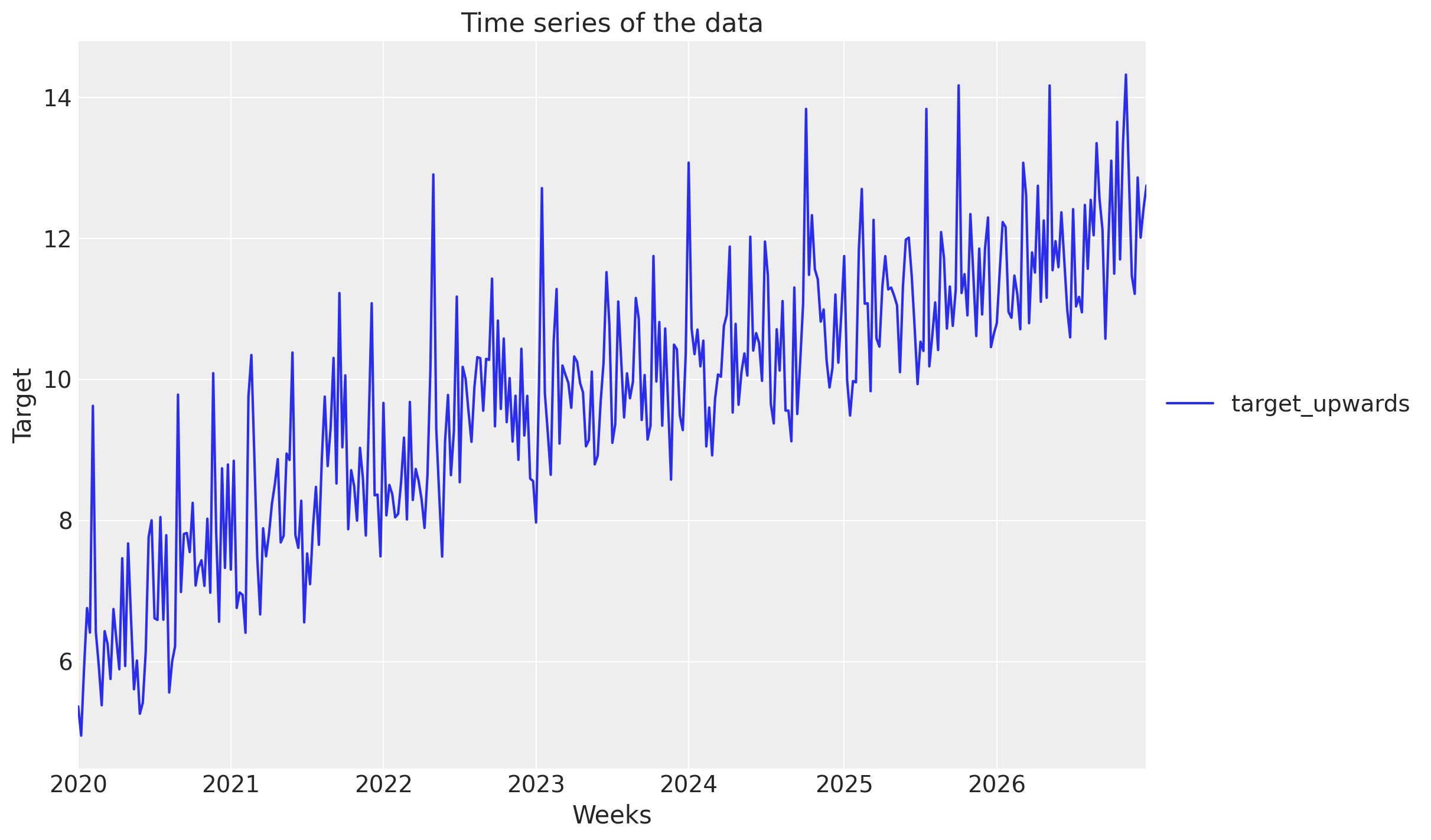
DATA[["Weeks", "target_upwards"]].set_index("Weeks").plot(ax=ax)
ax.set_title("Time series of the data")
ax.set_ylabel("Target")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5));
→ Split into train and test#
data_train = DATA.iloc[:-SPLIT_N]
data_test = DATA.iloc[-SPLIT_N:]
→ Fit model#
mmm_upwards = create_and_fit_mmm(
data_train, data_train["target_upwards"], target_column="target_upwards"
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 37 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2200 | 0 | 0.08 | 63 | |
| 2200 | 0 | 0.08 | 63 | |
| 2200 | 0 | 0.06 | 63 | |
| 2200 | 0 | 0.07 | 63 |
→ Posterior predictive check#
Predicting sales
# Plot whole period
plot_posterior_predictive(mmm_upwards, DATA["target_upwards"], label_y=-4)
# Zoom in on the years around train/test split
plot_posterior_predictive_zoomed(
mmm_upwards,
DATA["target_upwards"],
xlim=(date(2025, 1, 1), date(2026, 12, 1)),
arrow_xy=(date(2026, 5, 20), 12),
arrowtext_xy=(date(2026, 6, 20), 14),
label_y=-5,
);
Sampling: [intercept_baseline, y]
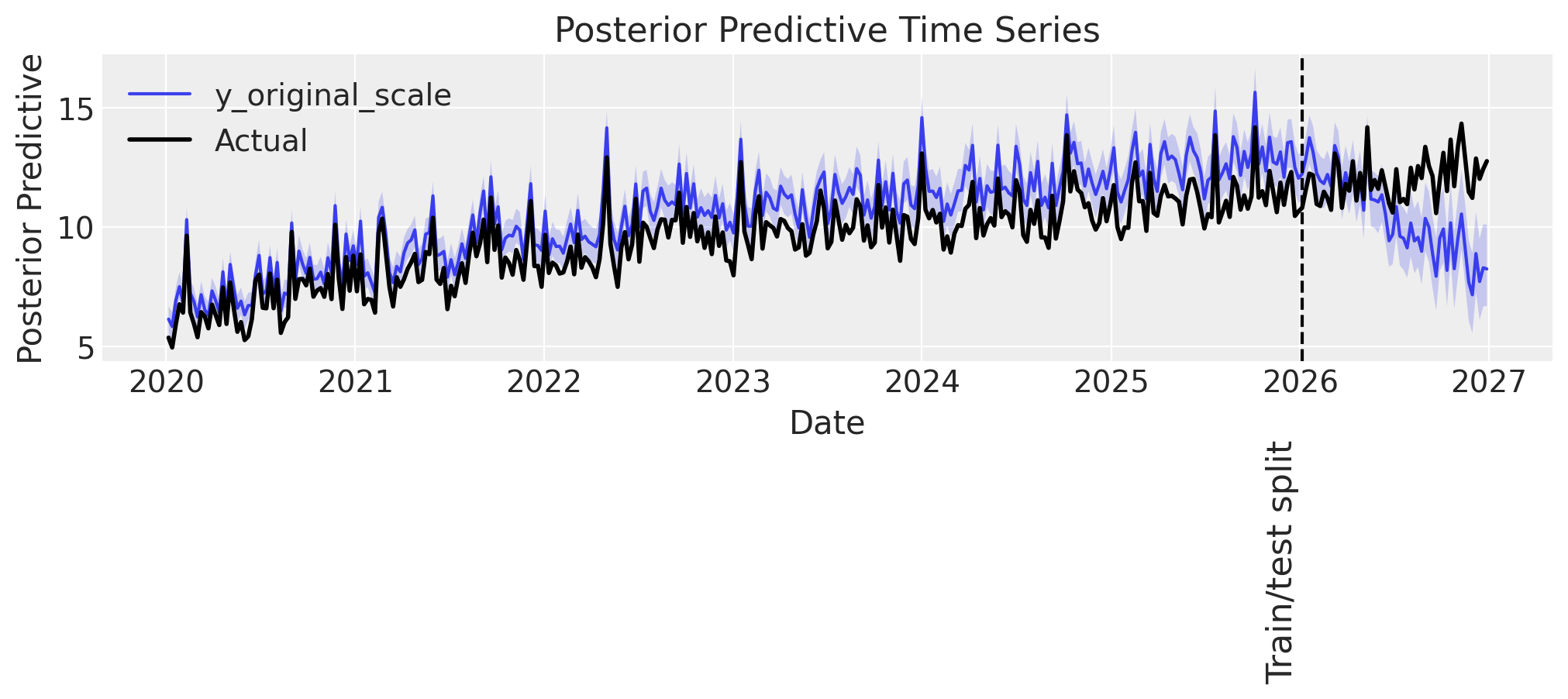
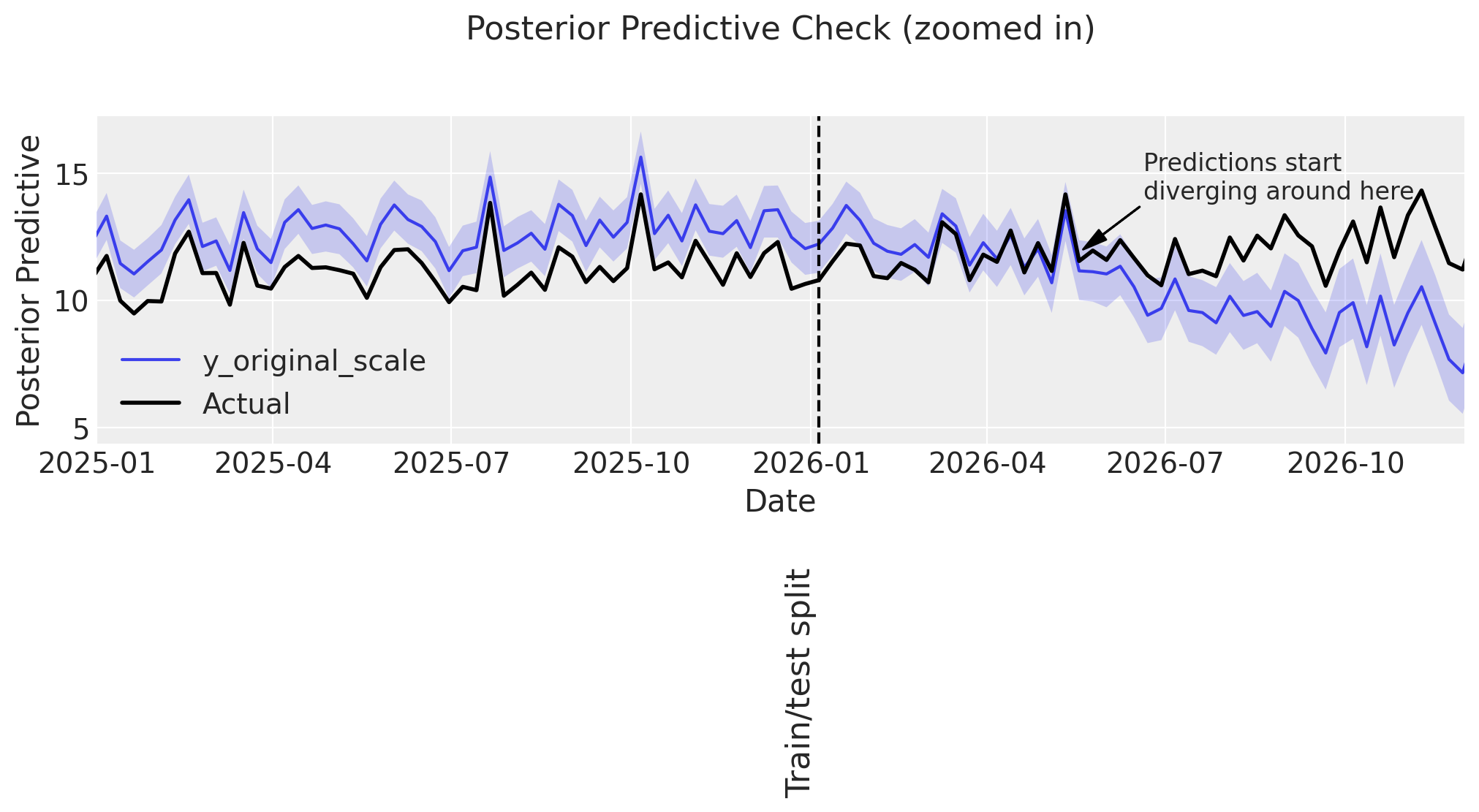
Observations:
👎 The model does not perform well in-sample. It seems to be overpredicting.
👎 Similar to before, predictions are accurate up to ~3-6 months into the test set, then start to deviate.
Predicting intercept
print_base_intercept(mmm_upwards)
plot_intercept_posterior_predictive(
mmm_upwards, synthetic_intercept_upwards, label_y=1
);
intercept_contribution: 5.944
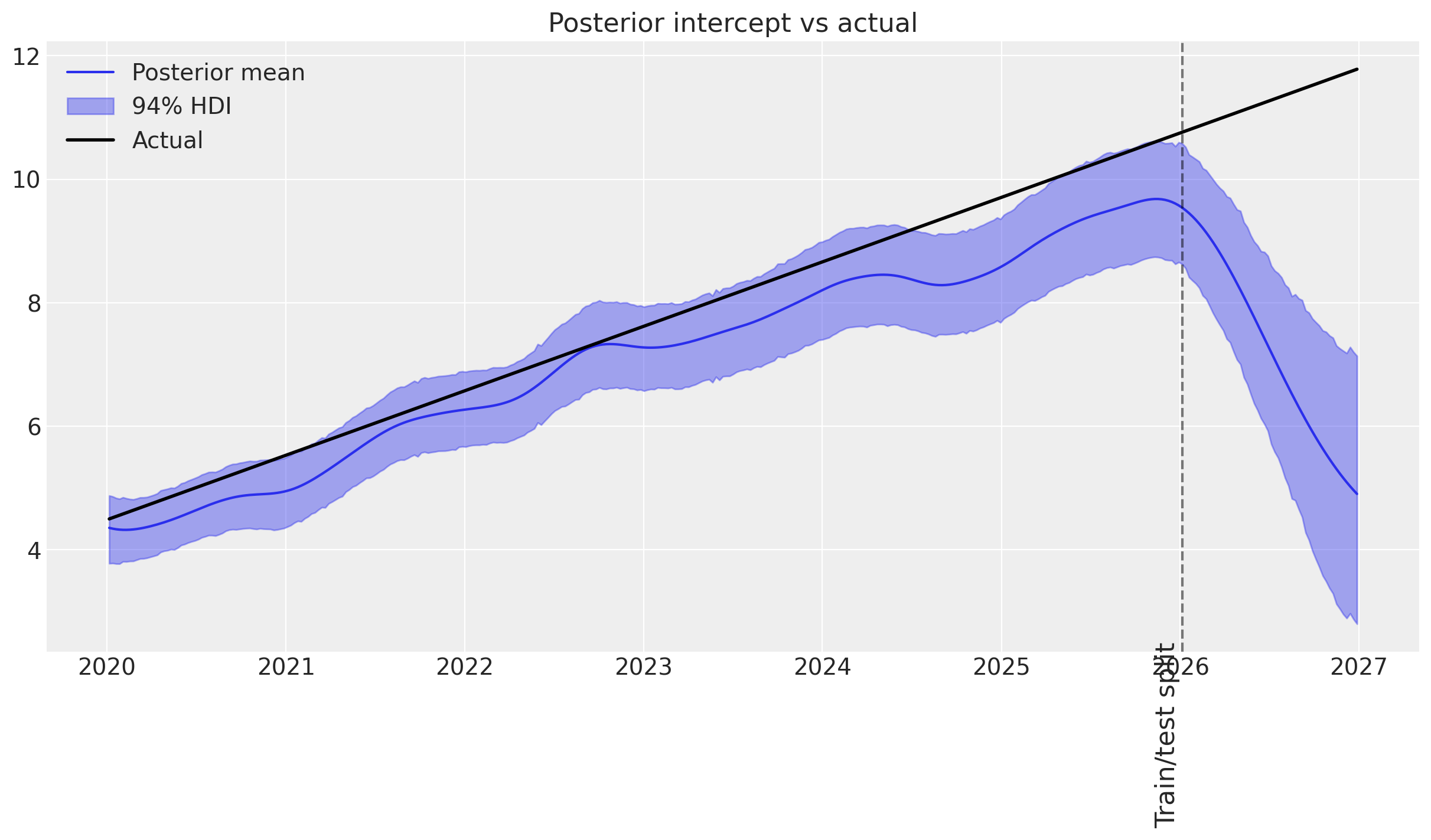
Observations:
👎 In-sample does not follow the synthetic trend with most observations outside the HDIs.
👎 Out-of-sample, the GP reverts to its prior mean.
It’s quite clear from this example, that if you have a steep upward trend in your sales data that you have reason to expect will continue, you probably should not use a GP to model the intercept. Instead, you may use linearly increasing control variables.
Example 3: Unexpected events#
This section repeats the procedure except with an intercept of 5, except with intermittent spike/dip events. Each event could be a competitor product launch, a global pandemic, an unusually sunny spring, or another impactful, unexpected event.
→ Simulate sales#
def create_yearly_series() -> npt.NDArray:
rng: np.random.Generator = np.random.default_rng(42)
# Get the number of weeks in each year
weeks_in_years = DATA.Weeks.dt.year.value_counts().sort_index()
# Create a flat and occasionally spiky time-series, in one-year increments
series = np.zeros(sum(weeks_in_years))
for i, num_weeks in enumerate(weeks_in_years):
# Random spikes in sales
series[sum(weeks_in_years[:i]) : sum(weeks_in_years[: i + 1])] = (
(rng.normal(size=num_weeks) - 0.5).cumsum().clip(0)
)
# Random dips in sales
series[sum(weeks_in_years[:i]) : sum(weeks_in_years[: i + 1])] += -(
(rng.normal(size=num_weeks) - 0.5).cumsum().clip(0)
)
return series
synthetic_intercept_events = create_yearly_series() + 5
DATA["target_events"] = synthesize_and_plot_target(synthetic_intercept_events)
→ Split into train and test#
data_train = DATA.iloc[:-SPLIT_N]
data_test = DATA.iloc[-SPLIT_N:]
→ Fit model#
mmm_events = create_and_fit_mmm(
data_train, data_train["target_events"], target_column="target_events"
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 21 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2200 | 3 | 0.12 | 31 | |
| 2200 | 4 | 0.11 | 31 | |
| 2200 | 2 | 0.14 | 31 | |
| 2200 | 1 | 0.11 | 31 |
→ Posterior predictive check#
Predicting sales
# Plot whole period
ax = plot_posterior_predictive(mmm_events, DATA["target_events"], label_y=2)
# Zoom in on the years around train/test split
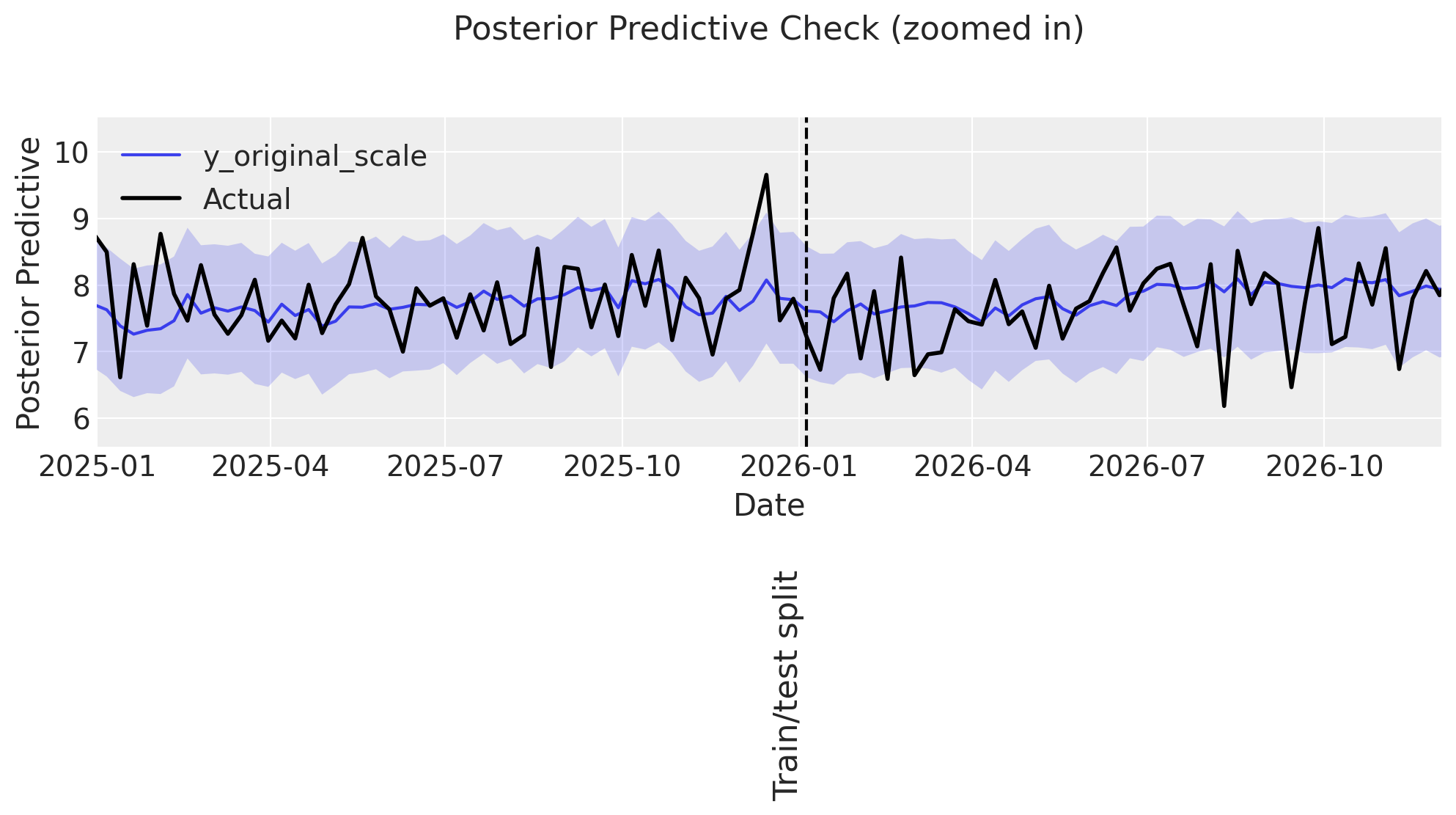
ax = plot_posterior_predictive_zoomed(
mmm_events,
DATA["target_events"],
xlim=(date(2025, 1, 1), date(2026, 12, 1)),
arrow_xy=(date(2026, 3, 20), 12),
arrowtext_xy=(date(2026, 4, 20), 20),
label_y=2,
)
Sampling: [intercept_baseline, y]
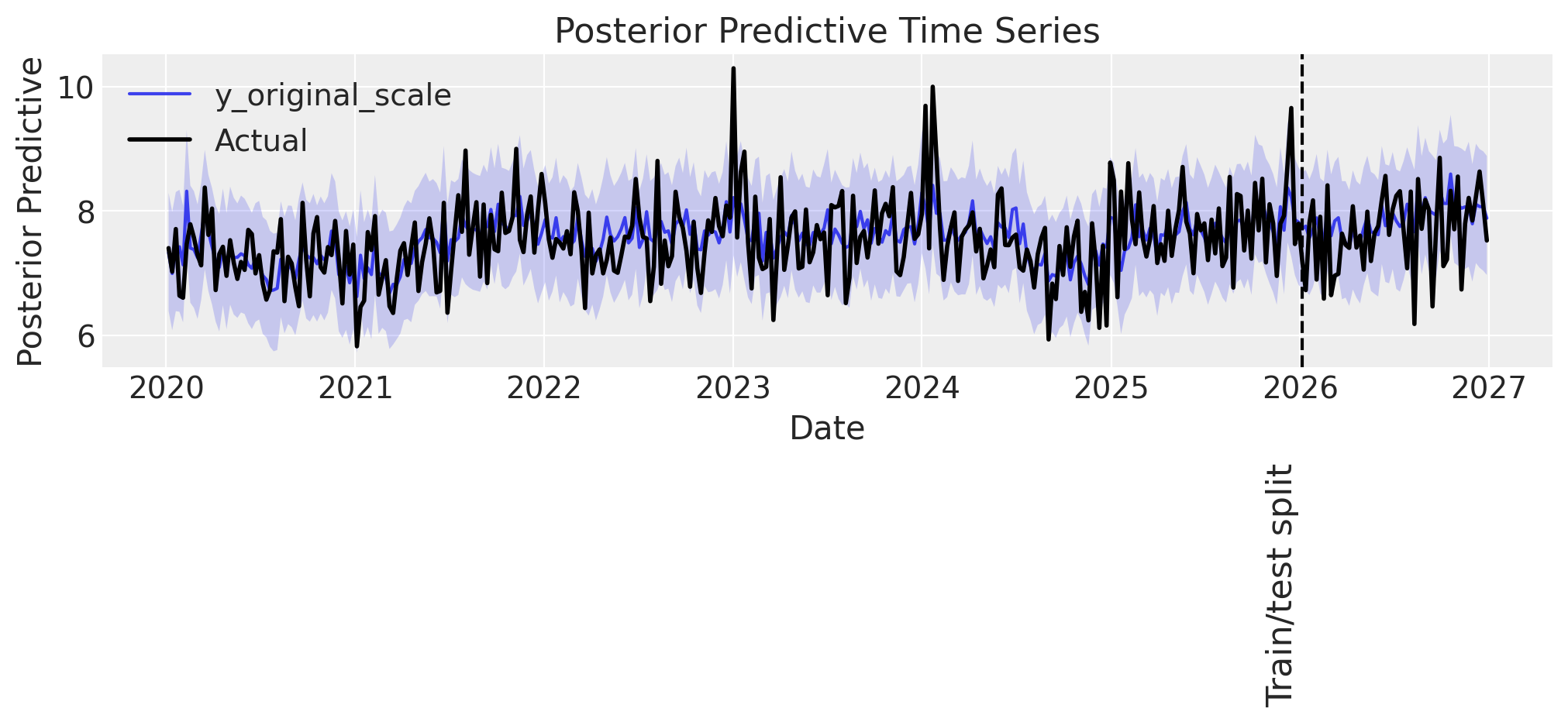
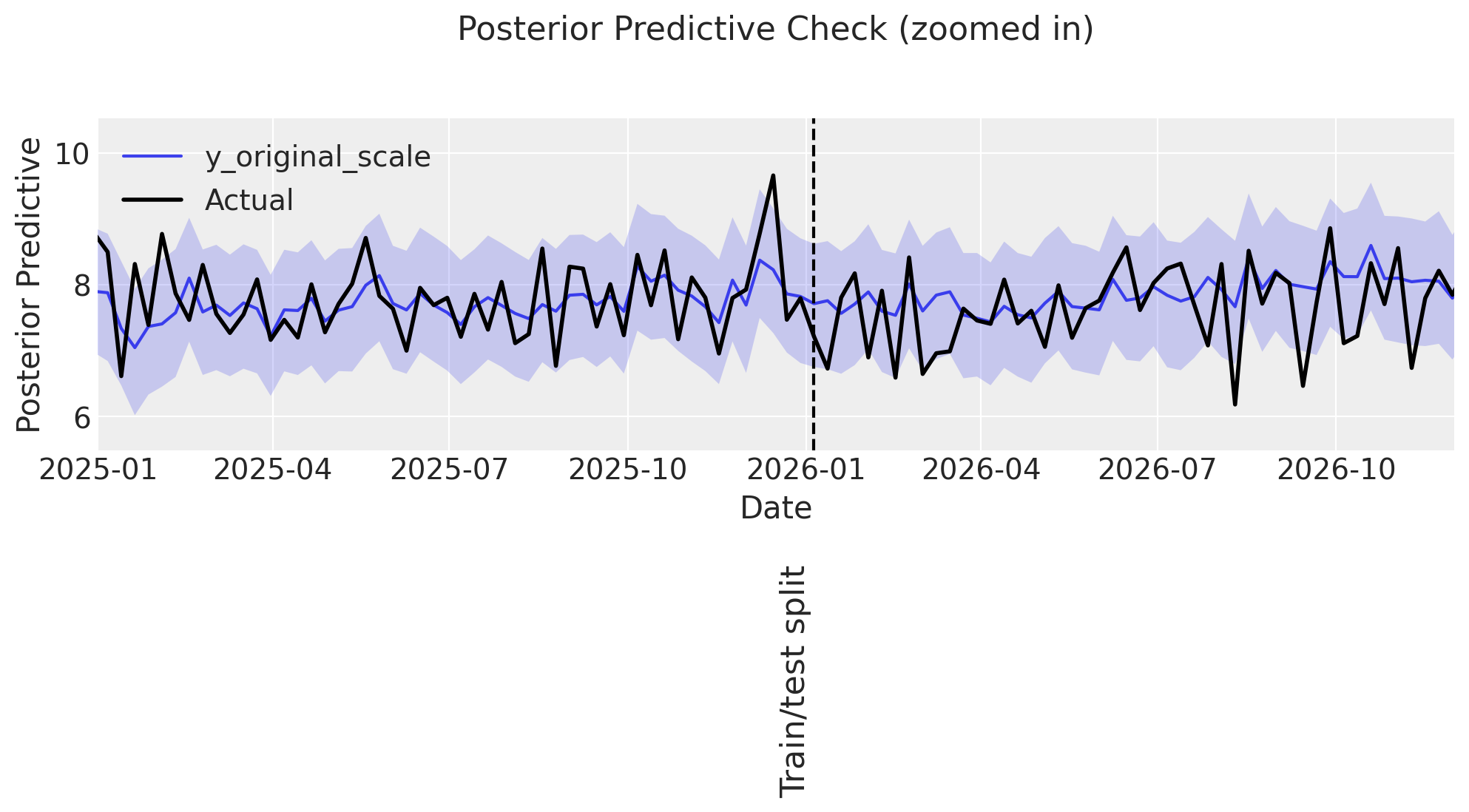
Some observations:
👎 The model predictions have large uncertainty, more than observed in the previous examples.
Predicting intercept
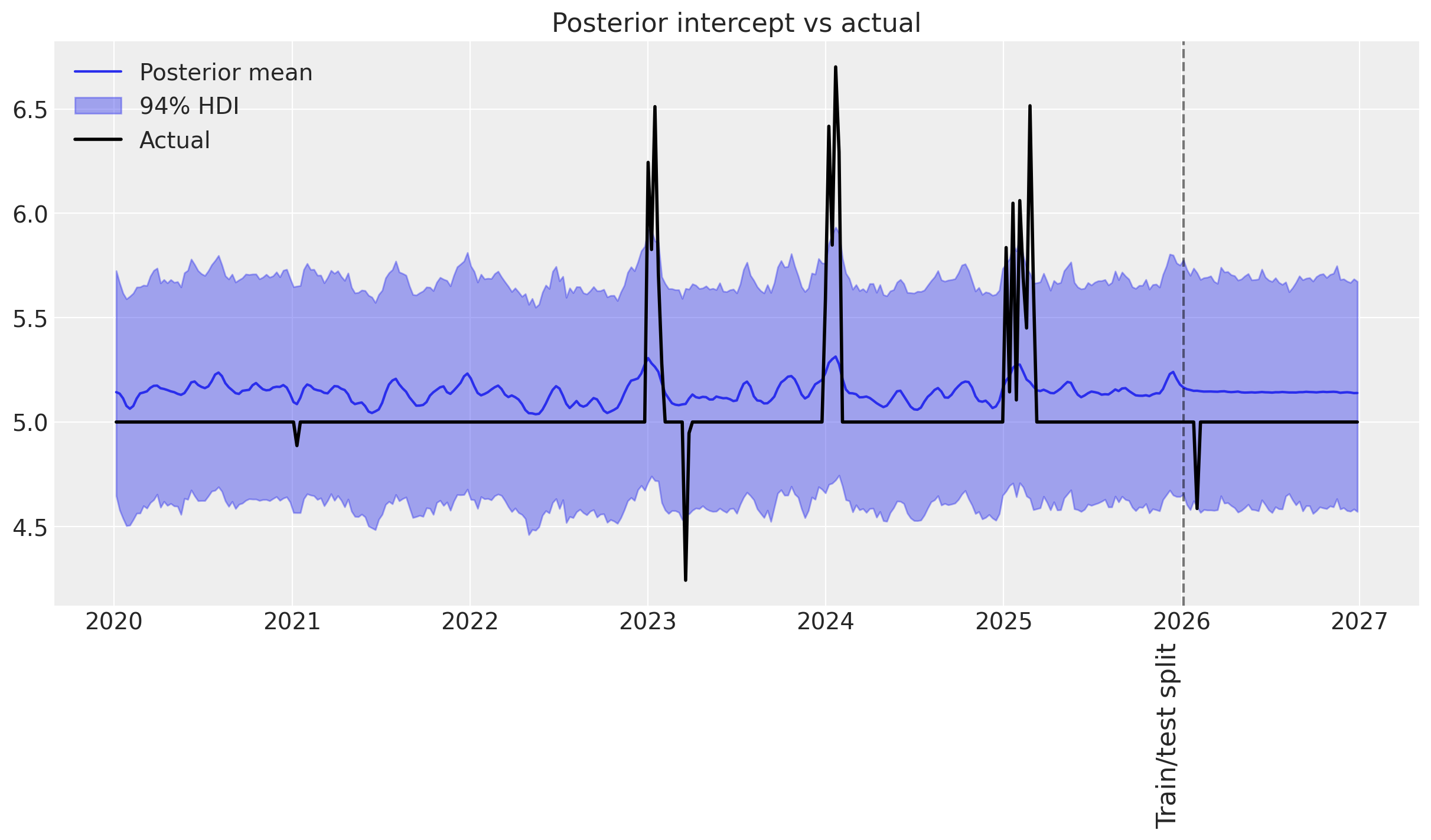
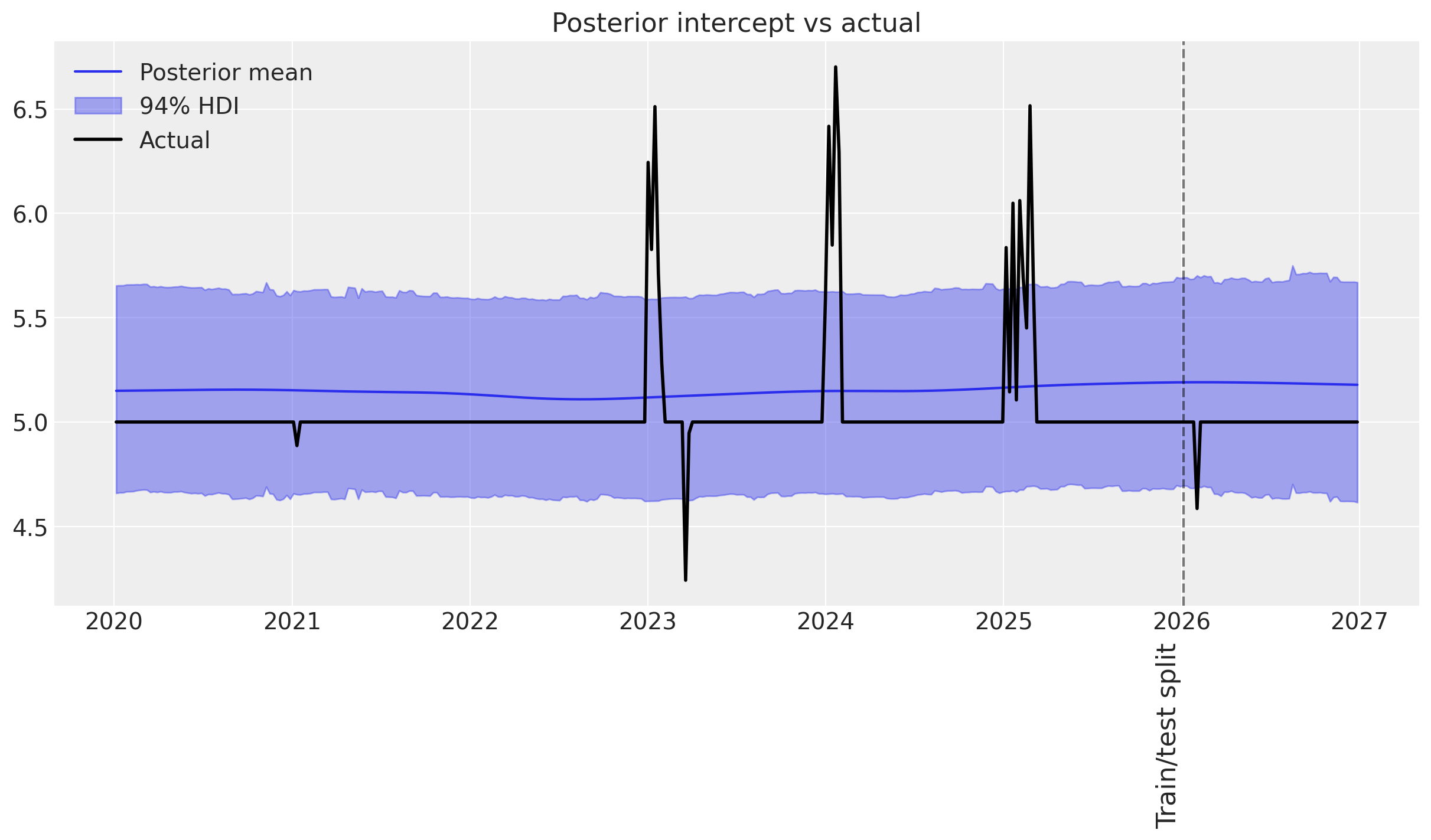
ax = plot_intercept_posterior_predictive(
mmm_events, synthetic_intercept_events, label_y=3.5
)
print_base_intercept(mmm_events)
intercept_contribution: 5.119
Judging from the posterior predictive distribution of the time-varying intercept, there is a problem with the model.
We observe that:
👎 The model overestimates the intercept a lot.
🤷♂️ Only the two major events are captured by the time-varying intercept.
👎 Overall uncertainty is greater than in the previous examples.
This is a strong indication that the time-varying intercept prior may not be well parameterized. Since the events that we synthesize happen on shorter time scales than the trends we modeled previously, it is likely that the mean of the length-scale prior is too high (default is two years).
💡 Let’s try to refit the model with a shorter length scale prior mean of one year (52.18 weeks).
model_config = {
"intercept": Prior("LogitNormal", sigma=0.1), # 👈 Positive baseline intercept
"intercept_tvp_config": HSGPKwargs(
m=500, L=375.6, eta_lam=1.0, ls_mu=52.18, ls_sigma=5.0, cov_func=None
),
}
mmm_events_short_ls = MMM(
date_column="Weeks",
target_column="target_events",
channel_columns=COORDS["media"],
control_columns=COORDS["control"],
adstock=GeometricAdstock(l_max=10),
saturation=LogisticSaturation(),
time_varying_intercept=True, # 👈 Keep this as True
sampler_config=sampler_config,
model_config=model_config,
)
# Build the model
mmm_events_short_ls.build_model(X=data_train, y=data_train["target_events"])
# Add original scale contribution variables for later analysis
mmm_events_short_ls.add_original_scale_contribution_variable(
var=["channel_contribution", "control_contribution", "intercept_contribution", "y"]
)
# Fit the model
mmm_events_short_ls.fit(data_train, data_train["target_events"]);
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for 17 seconds
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2200 | 1 | 0.14 | 31 | |
| 2200 | 0 | 0.17 | 31 | |
| 2200 | 1 | 0.15 | 31 | |
| 2200 | 1 | 0.14 | 31 |
# Plot whole period
ax = plot_posterior_predictive(mmm_events_short_ls, DATA["target_events"], label_y=2.5)
# Zoom in on the years around train/test split
ax = plot_posterior_predictive_zoomed(
mmm_events_short_ls,
DATA["target_events"],
xlim=(date(2025, 1, 1), date(2026, 12, 1)),
arrow_xy=(date(2026, 3, 20), 12),
arrowtext_xy=(date(2026, 4, 20), 20),
label_y=2,
annotation_text="Hard to say exactly where\npredictions start to diverge\nmaybe here?",
)
Sampling: [intercept_baseline, y]

plot_intercept_posterior_predictive(
mmm_events_short_ls, synthetic_intercept_events, label_y=3.5
);
print_base_intercept(mmm_events_short_ls)
intercept_contribution: 5.110
Sidenote: While the very-small events are still not captured perfectly, this may be remedied with a more complex covariance function supplied through the model_config, although these events are likely below the minimal detectable effect size in this example.
Conclusion#
In this notebook, we have demonstrated how to use a time-varying parameter in a marketing mix model using pymc-marketing. We have shown how the model can capture yearly seasonality (with moderate success 🤷♂️), upward trending sales (not very well 👎), and random/unexpected events (very well 🎉). In summary, we show that a time-varying intercept, as modeled using a Gaussian Process (GP), is highly appropriate for modeling random events that cannot otherwise be accounted for in the model, whereas regular patterns that may influence baseline sales such as seasonality and constant demand increase are better modeled using a Fourier or linear basis.
In a nutshell
GPs are great at capturing patterns that are not easy/possible to extrapolate, and in turn, they cannot well extrapolate simple patterns like seasonality or increasing trends. For such cases, a Fourier basis or similar might be more appropriate. However, for explaining temporal variance that no other model component can account for—like the impact of an unexpected event—a time-varying intercept is great!
When should I use a time-varying intercept?
If you suspect that your baseline sales fluctuate over time due to factors beyond seasonality, constant growth, or explicitly modeled controls, consider using a time-varying parameter. The time-varying intercept is like a catch-all for unexplained variance in your sales data.
How should I parameterize my time-varying component?
We have defined some sensible defaults, and in most cases, they are adequate. But if you have unexplained variance in your sales that occur on short time scales, you may—as in the example above—experiment with lowering the length-scale prior mean. If you need greater fidelity in the frequencies that the GP can capture, and can live with longer sampling times, you can also increase the number of basis functions model_config['intercept_tvp_config'].m from 200 (default) to a higher number. Finally, if you believe you have events affecting your sales on, say, two separate time scales, you can supply a new covariance function through model_config['intercept_tvp_config'].cov_func, which is the sum of two independently defined covariance functions—each with a length-scale prior mean that matches the given time scales you expect in your data.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,pymc,pymc_marketing,numpyro
Last updated: Fri, 23 Jan 2026
Python implementation: CPython
Python version : 3.13.11
IPython version : 9.9.0
pytensor : 2.36.3
pymc : 5.27.0
pymc_marketing: 0.17.1
numpyro : 0.19.0
arviz : 0.23.0
matplotlib : 3.10.8
numpy : 2.3.5
pandas : 2.3.3
pymc : 5.27.0
pymc_extras : 0.7.0
pymc_marketing: 0.17.1
Watermark: 2.6.0